

随着企业数据量的增长,管理和整合多种数据库成为了一大挑战。为了解决这一问题,专利 CN111339081A 提出了 “自动收集异构数据库表目录的方法和系统” ,通过高度自动化的解决方案,提升数据提取效率高达 70%,并 减少人工部署和验证时间 90%,大幅优化企业的数据管理流程。这项技术不仅能显著提高 ETL(Extract, Transform, Load)流程的效率,还通过智能化的自动监控,彻底简化了数据整合与验证的工作。
专利背景 #
在现代企业中,数据通常分布在多种数据库中。由于数据结构和类型的差异,信息的收集和整合过程繁琐且耗时。该专利旨在通过自动化技术,高效从不同数据库系统中收集表目录信息,显著优化数据提取和分析流程。
专利概述 #
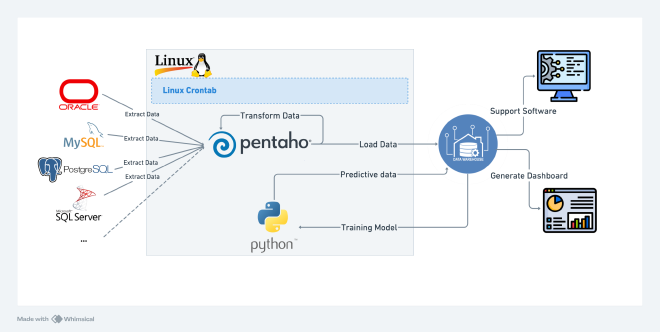
专利 CN111339081A 提出了一个自动化的方法,能够从这些异构数据库中高效收集基本信息。该方法的主要步骤包括:
- 数据收集:系统自动收集各个数据库的基本信息,生成数据库表的初步列表。
- 数据分析:对收集到的信息进行分析,以识别数据之间的关系。
- 监控数据质量指标:实时监控数据质量指标,以快速响应问题,保障数据分析的可靠性。
- Data Tool 使用:利用 Pentaho-Kettle 和 Python 进行数据的提取、转化和加载,将提取到的数据流向数据仓库,为业务使用提供支持。
- 预测建模:基于收集到的数据,使用 Python 开发的算法进行预测建模,优化计算出下一次执行提取的顺序,从而提高数据提取的效率。
- CI/CD 流程:开发过程中,利用 Jenkins 等工具自动化数据管道的测试和部署,提高开发效率。
- 定期备份与恢复:自动化数据备份和恢复流程,确保数据安全性与可用性,防止数据丢失。
主要优势 #
- 提高效率:通过自动化的数据收集,显著提高了在不同数据库环境中管理数据的效率,减少了人工干预。
- 增强管理:提供了一个结构化的视图,使企业能够更好地了解各类数据的存储情况,并优化数据处理流程。
优化建议 #
经过持续学习和项目实践,我认为该项目在实际生产应用中有一些可以优化的地方。
-
数据架构设计
数据湖与数据仓库结合:考虑采用数据湖(如 AWS S3、Azure Data Lake Storage、GCP Cloud Storage )与数据仓库(如 Redshift、Azure Synapse、BigQuery )相结合的架构,以支持多种数据处理需求,带来以下优势:
- 灵活性:数据湖支持多种格式(如结构化、半结构化和非结构化数据),使企业能够灵活处理不同类型的数据。数据仓库则专注于高性能的结构化数据查询,适合业务分析。
- 成本效益:使用数据湖存储大量原始数据,企业可以减少数据存储成本,特别是在处理大规模数据时。相比之下,数据仓库可用于高频次、低延迟的数据分析,提供更快的查询性能。
- 数据整合:通过数据湖,可以将来自多个来源的数据(如 IoT 设备、社交媒体、日志文件等)集中存储,从而提供一个统一的数据源,支持后续的数据分析和挖掘。
- 支持实时分析:结合数据湖和数据仓库架构,可以实现实时数据处理。数据湖中的流数据可通过数据仓库进行实时分析,帮助企业快速做出业务决策。
- 数据治理与合规性:数据湖和数据仓库结合可以更好地管理数据的生命周期,确保数据的安全性和合规性,同时提供访问控制和审计功能。
- 增强数据科学能力:数据湖可以存储大量的历史数据,供数据科学团队进行机器学习和深度学习模型训练,而数据仓库则支持更高效的数据分析。
通过结合数据湖与数据仓库的架构,企业能够更好地应对不断变化的数据需求,提高数据管理的灵活性和效率。
-
数据ETL/ELT流程优化
使用现代 ETL 工具:采用 Apache Airflow、DBT 等现代工具进行数据管道的管理和监控,确保数据的透明性和可追溯性。
- 任务调度方面,可以考虑使用 Apache Airflow 代替传统的 Linux cron 作业。Airflow 具备以下优势:
- 可视化和监控:现代 ETL 工具通常提供用户友好的界面,允许团队可视化数据流和任务状态,便于监控和管理数据管道的运行。
- 任务依赖管理:Apache Airflow 支持复杂的任务依赖关系,可以确保任务按特定顺序执行,这在处理复杂的 ETL 流程时至关重要。
- 重试机制:Airflow 提供内置的重试机制,可以在任务失败时自动重新执行,提高了任务的可靠性。
- 灵活性与扩展性:Airflow 允许用户通过代码定义数据管道,便于版本控制和快速迭代,同时也支持与多种数据源和目标的集成。
- 动态调度:Airflow 支持基于条件动态生成任务,允许用户根据数据的变化自动调整 ETL 流程,提高了数据处理的灵活性。
- 开放源代码与社区支持:Apache Airflow 是开源项目,拥有活跃的社区,用户可以获得持续的更新和支持,同时可以根据需求定制功能。
- 使用 DBT 的优势
- 数据建模与转换:DBT 专注于数据转换,提供简洁的 SQL 语法,使数据团队能够轻松编写和管理数据模型。
- 版本控制:DBT 允许将数据转换过程纳入版本控制,使团队能够追踪更改,确保数据处理的透明性和可追溯性。
- 自动化文档生成:DBT 能自动生成数据文档,提供清晰的数据字典,有助于数据治理和合规性。
通过采用现代 ETL 工具,企业可以提高数据管道的管理效率,确保数据的透明性、可追溯性和可靠性,为后续的数据分析提供更坚实的基础。
- 任务调度方面,可以考虑使用 Apache Airflow 代替传统的 Linux cron 作业。Airflow 具备以下优势:
-
数据质量管理
- 实施数据验证:使用数据质量工具(如 Great Expectations)实现自动化的数据质量检查,减少人为干预,提高效率。
- 元数据管理:建立元数据管理系统,以追踪数据来源、数据变更和数据使用情况,帮助团队理解数据上下文和业务含义。
-
容器化
- 使用 Docker 和 Kubernetes:将数据处理和 ETL 流程容器化,使用 Docker 来创建轻量级、可移植的容器,确保应用程序在不同环境中的一致性。借助 Kubernetes 来管理和编排容器,支持自动扩展和高可用性。
- 环境一致性:容器化可以消除“在我机器上可以运行”的问题,确保开发、测试和生产环境的一致性,减少环境配置错误。
- 简化依赖管理:将应用及其依赖打包在一起,简化了软件的部署过程,便于版本管理和快速迭代。
-
监控与性能优化
- 实时监控:使用监控工具(如 Prometheus、Grafana)对数据管道和数据库性能进行实时监控,及时发现并解决问题。
- 性能调优:定期评估查询性能,使用数据库的分析工具(如 EXPLAIN 语句)识别慢查询,优化索引和查询逻辑。
结语 #
参与此专利的研发,不仅让我对不同数据库的管理有了更深刻的理解,也提升了我的技术能力。我相信,随着数据管理技术的不断发展,类似的创新将会越来越重要,为企业的数据处理提供更多便利。