

With the growth of enterprise data, managing and integrating multiple databases has become a significant challenge. Patent CN111339081A , titled “Automatic collection method and system for table directory of heterogeneous database”, offers a highly automated solution that boosts data extraction efficiency by up to 70% and reduces manual deployment and verification time by 90%. This innovation dramatically enhances the efficiency of ETL (Extract, Transform, Load) processes, while intelligent automated monitoring simplifies the entire data integration and validation workflow.
Patent Background #
In modern enterprises, data is often scattered across various database systems. Differences in data structures and formats make the process of collecting and integrating information cumbersome and time-consuming. This patent proposes an automated approach to efficiently collecting table directory information from various database systems, significantly streamlining the data extraction and analysis process.
Patent Overview #
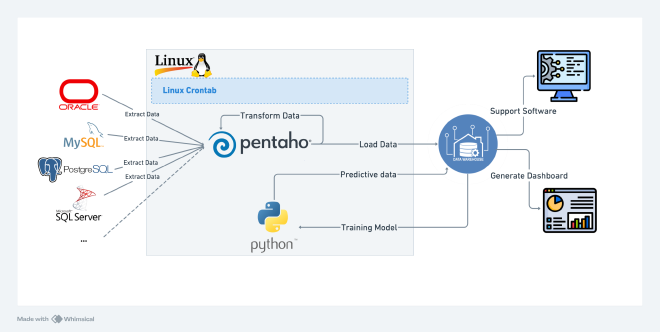
Patent CN111339081A describes an automated system for efficiently gathering basic information from heterogeneous databases. The key steps of this system include:
- Data Collection: The system automatically collects basic information from various databases, generating an initial list of database tables.
- Data Analysis: Collected information is analyzed to identify relationships between data.
- Monitoring Data Quality Metrics: Real-time monitoring of data quality metrics ensures the reliability of data analysis by quickly responding to potential issues.
- Data Tools: Tools like Pentaho-Kettle and Python are used to extract, transform, and load data into a data warehouse for business use.
- Predictive Modeling: The system uses Python-based algorithms to optimize the order of data extraction, improving efficiency.
- CI/CD Pipelines: Jenkins is used to automate testing and deployment of the data pipeline, streamlining development.
- Backup and Recovery: Automated backup and recovery processes ensure data security and availability, preventing data loss.
Key Advantages #
- Efficiency Gains: Automated data collection significantly improves data management across various database environments, reducing manual intervention.
- Enhanced Management: The system provides a structured view of database storage, enabling businesses to better understand and optimize data processing.
Optimization Suggestions #
Through continued learning and project practice, I’ve identified several areas for further optimization in real-world production environments.
1. Data Architecture Design #
Combining Data Lakes with Data Warehouses: A hybrid architecture that integrates data lakes (e.g., AWS S3、Azure Data Lake Storage、GCP Cloud Storage ) with data warehouses (e.g., Redshift、Azure Synapse、BigQuery ) would offer several benefits:
- Flexibility: Data lakes support multiple formats (structured, semi-structured, and unstructured), giving enterprises flexibility to process various data types. Data warehouses focus on high-performance querying, suitable for business analytics.
- Cost Efficiency: Storing large amounts of raw data in a data lake reduces storage costs. High-frequency, low-latency analyses can be performed in a data warehouse for better performance.
- Data Integration: A data lake enables centralized storage of data from multiple sources (e.g., IoT devices, social media, log files), providing a unified source for downstream analysis.
- Real-Time Analytics: By combining data lakes and warehouses, enterprises can perform real-time data processing. Streaming data in a data lake can be analyzed in real-time through the data warehouse.
- Data Governance and Compliance: This architecture improves lifecycle management of data, ensuring security and compliance, while offering access control and auditing features.
- Enhanced Data Science: A data lake stores vast amounts of historical data, ideal for machine learning and deep learning models, while the data warehouse supports efficient analytics.
By combining a data lake and warehouse architecture, businesses can better adapt to evolving data needs and improve management flexibility.
2. Optimizing ETL/ELT Processes #
Use Modern ETL Tools: Leveraging modern tools like Apache Airflow、DBT for managing and monitoring data pipelines ensures transparency and traceability.
-
Task Scheduling with Apache Airflow: Instead of relying on traditional Linux cron jobs, Apache Airflow offers:
- Visualization and Monitoring: Modern ETL tools provide user-friendly interfaces that allow teams to visualize data flows and task statuses, improving pipeline management.
- Dependency Management: Airflow supports complex task dependencies, ensuring that tasks execute in the correct order—essential for intricate ETL processes.
- Retry Mechanisms: Built-in retry functionality in Airflow ensures that tasks automatically rerun upon failure, improving reliability.
- Flexibility and Scalability: Airflow allows users to define data pipelines via code, enabling version control and rapid iteration. It also supports integration with a variety of data sources and targets.
- Dynamic Scheduling: Airflow supports conditional task generation, enabling pipelines to adjust dynamically based on changes in the data, offering more processing flexibility.
- Open Source and Community Support: As an open-source project, Airflow benefits from a large community, continuous updates, and customization options.
-
Advantages of DBT:
- Data Modeling and Transformation: DBT focuses on data transformation, providing simple SQL syntax to enable teams to easily write and manage data models.
- Version Control: DBT allows the transformation process to be versioned, enabling teams to track changes and ensure transparency and traceability.
- Automated Documentation: DBT automatically generates data documentation, creating clear data dictionaries that aid in governance and compliance.
Using modern ETL tools can significantly enhance pipeline management, ensuring transparency, traceability, and reliability, laying a solid foundation for subsequent data analysis.
3. Data Quality Management #
- Implement Data Validation: Tools like Great Expectations can automate data quality checks, reducing manual intervention and improving efficiency.
- Metadata Management: Establish a metadata management system to track data origins, changes, and usage, helping teams understand data context and business significance.
4. Containerization #
- Using Docker and Kubernetes: Containerize data processing and ETL workflows using Docker to create lightweight, portable containers, ensuring consistency across environments. Use Kubernetes for container orchestration, supporting autoscaling and high availability.
- Environment Consistency: Containerization eliminates the “works on my machine” problem, ensuring consistency between development, testing, and production environments, reducing configuration errors.
- Simplified Dependency Management: Applications and their dependencies are bundled together, simplifying deployment, version management, and rapid iteration.
5. Monitoring and Performance Optimization #
- Real-Time Monitoring: Use tools like Prometheus and Grafana to monitor data pipelines and database performance in real-time, quickly identifying and resolving issues.
- Performance Tuning: Regularly evaluate query performance using database analysis tools (e.g.,
EXPLAINstatements), optimizing indexes and query logic to enhance performance.
Conclusion #
Contributing to the development of this patent has deepened my understanding of managing heterogeneous relational databases and enhanced my technical capabilities. I believe that as data management technologies continue to evolve, innovations like this will become increasingly critical, providing more convenience for enterprise data processing.